
I have this curse where I keep finding heisenbugs not only in the software I use, but also in hardware… The difference being that, unlike software misbehavior, hardware issues take me months to figure out. But hey, they say I’m a persistent bastard.
This blog post is mainly a tale about computer hardware, which is a bit unusual on this blog, but it ties back into software and Linux graphics troubleshooting, so there should be something interesting for everybody. Enjoy a solid 20 minutes of reading my walk through the inferno, hopefully you’ll find something insightful or funny in my unreasonably persistent path to hardware salvation. Anyway, the reading time doesn’t seem that long when it took me 10 months to write this post over 37 revisions 😉
This divine comedy is divided in a série of chants:
- “Prologue: Beware of Hardware” (two short case studies of strange hardware bugs from years past)
- “I once thought 4GB of RAM ought to be enough for anybody” (a tale of modern web browsing, and of operating system kernels gone rogue)
- “Overwhelming power: the new Kusanagi” (this is where today’s hardware story begins)
- “The quest for stability begins” (my descent into Hell)
- “Finding the culprit” (meeting with Virgilio)
- “Reworking my workstation” (salvation)
- Epilogue
Prologue: Beware of Hardware

A bit over ten years ago (jeez, we’re old) herr Schroeder gave me this advice: “Never skimp on RAM or power supplies, because troubleshooting issues that involve these is so damned hard” (I’m loosely quoting from memory). Sage advice, but somehow all the hardware heisenbugs I encountered so far turned out not to be in those particular components. For example:
- Some years ago, I spent months trying to figure out why my aunt’s brand new computer running Centos would experience random kernel panics. Whenever she would bring the computer to my office I would be unable to reproduce the issue no matter how hard I tried to “break it”, and when it went back home the issue would start reappearing again (I saw it with my own eyes). So I tested for peripherals combinations, software combinations, network combinations, tried torture-testing the thing with various benchmarks (including repeatedly opening and closing hundreds of tabs at once, heating up the system)… until I realized that the key to the problem was the fact that the computer was being physically transported across the two locations. Eventually I found the cause: a faulty SATA cable connected to the SSD!
- Last year, it took me months (again) to figure out why my father’s desktop computer had started randomly freezing (the applications on the screen, and the mouse cursor, would just lock up out of the blue). Here again I did stress tests, tried systematically reverting and bisecting recent software updates to figure out what had “broken” the system—after all, the computer hadn’t moved at all, it could only be due to some software regression, right? Until I bothered to open the case and found capacitor plague.

Well, today’s blog post is another story about taking months to find the solution to a problem—except this time it was worse. Much, much worse. Grab yourself a beer in the fridge.
I once thought, “4 GB of RAM ought to be enough for anybody”
These days, if you’re a marketeer or hardcore project manager, it seems 5-8 gigabytes of RAM is no longer enough to do anything serious in parallel to web browsing on a GNU+Linux system. See also:
- the website obesity crisis,
- the disease of web apps being used as replacements for native desktop applications,
- my seven-years-old rant on Firefox—which, given that Firefox is more “globally memory-efficient” than Chrome/Chromium these days, is in big part being fixed this year as we now have Electrolysis and Quantum Flow startup times (with Firefox 55, my startup time went from 1 minute and 13 seconds to… 5.8 seconds).
Since I have a lot of tabs open in parallel to my research or graphics work, I tend to run into OoM conditions all the time, no matter which web browser I use. Thanks, web 2.0!

The issue wouldn’t be so bad if the Linux kernel actually did its job, but it doesn’t: when your RAM is full, the Linux kernel will just start trashing your hard disk for no good reason, and if you’re lucky after 30 minutes it might figure out “Oh, that web browser process thing that grew at hundreds of megabytes per minute or tried to allocate 20 times the amount of available RAM, maybe that’s the one I should kill instantly?”… Or, to put things succintly:
@mairin I wish the OOM killer ignored small fry and chased down the real outlaws. Like that Firefox bastard that terrorizes the town.
— Jeff 🎆 (@nekohayo) April 29, 2014
https://twitter.com/hergertme/status/704607950829068288
This is in addition to having our desktop environments slow to a crawl whenever there is I/O (hard disk) trashing going on:
https://twitter.com/garrett/status/740577649668546560
I suspect there is only a handful of us crazies (“power users”) acutely aware of these issues. Not everybody experiences or notices this, but just like video tearing in X.org or the general framerate dropping over time in GNOME Shell, it’s the kind of thing where “once you become aware of its existence, you cannot un-see it”.
Overall, the Linux kernel is still pretty subpar (I’m being polite here) for “workstation” desktop usecases. It’s so, so incredibly bad at handling memory and I/O. Throughout the years, it has been the #1 component of my system that regularly made me want to throw furniture across the room as I hit “out of memory” conditions that destroyed my productivity. All I wanted was to do design+photography work in parallel to tons of online research!
Overwhelming power:
the new Kusanagi
Hence, after a decade of waiting for the Linux kernel to get its act together, I gave up and decided to nuke the problem from orbit by replacing my “perfectly good” (but maxed out) computer—Kusanagi—by a workstation so stupidly powerful that I would not even be affected by the kernel’s lackluster resources management anymore.
Since this is GNU+Linux we’re talking about, I would just have to transplant its cyberbrain (hard drives and SSDs, containing the “ghost”) into the new “shell”—a trivial operation, no need to reinstall the operating system or anything.

So, at the end of 2015, I bought this completely overpowered 2nd-hand cyborg shell, for about 370 Canadian yen:

Er, I mean:

…a second-hand Dell “Precision T3500” workstation maxed out with 24 gigabytes of RAM and an 8-cores Xeon processor, lazily named “Kusanagi 2.0”. While it was made in 2009, it was a workstation-class machine, and remains completely overkill even today, in 2016 2017 2018.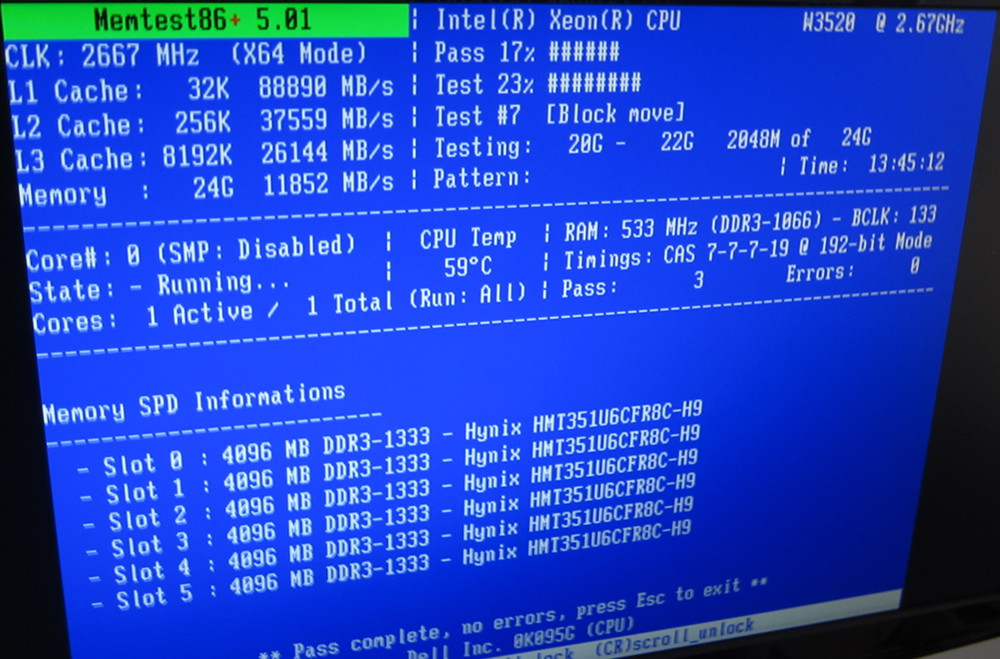
This would let me kill two birds with one catapult boulder:
- Accomplish more parallel work, and be more productive in my daily work—I was utterly sick of “having to think about RAM” or experiencing debilitating lockups. I want to think about business problems, not the boundaries of my tools.
- Accomplish more complex work, such as completing a special painting project where I needed at least 10 gigabytes of RAM to work with (Kusanagi 1.0 “only” had 5 GB).
I did not expect to see an application-level performance difference compared to my previous quad-core Inspiron 530n, but there definitely is one—I was shocked at how ridiculously faster my “new” computer turned out to be, with the Xeon and DDR3 RAM (vs DDR2). With Firefox (before the Quantum days) or GTG, you could feel applications launching and responding noticeably quicker. Neat!

Basic care and tweaks
First, the machine needed some cleanup (click to enlarge):


Then, I removed the metal faceplate in the front and custom-built an air intake dust filter—using stockings, some L-shaped metal enclosed in a plastic frame to create the filter’s support system, and some hooks to hold it in place.

It now had a sober, unassuming “serious business” look, which I rather liked for its simplicity (and the lack of flashiness makes it less appealing to thieves):

Here is the resulting battlestation:

With this “new” super powerful computer, I was ready to be immediately productive, right? Well, almost.
The quest for stability begins
(descent into Hell)

There turned out to be just one problem with the new workhorse: after a few weeks of use, I realized I kept running into a strange issue where the video card would randomly die on me and the Linux kernel would panic, freezing the whole machine.
It would happen at any time: often when doing something that stresses the GPU (like watching videos or using an OpenGL/WebGL application), but also (a bit more rarely) when not doing anything in particular; I could be just sitting and staring at my desktop when suddenly the monitor would turn off and I would get the same errors in dmesg:
radeon 0000:02:00.0: ring 0 stalled for more than 10252msec radeon 0000:02:00.0: GPU lockup (current fence id 0x00000000006c9132 last fence id 0x00000000006c928b on ring 0) radeon 0000:02:00.0: failed to get a new IB (-35) [drm:radeon_cs_ioctl [radeon]] *ERROR* Failed to get ib ! BUG: unable to handle kernel paging request at ffffc90404239ffc IP: [<ffffffffa013736a>] radeon_ring_backup+0xda/0x190 [radeon] PGD 6068a8067 PUD 0 Oops: 0000 [#1] SMP
It was infuriating. I had this superb, powerful machine… that I couldn’t use except for the lightest tasks (like basic web surfing, email, office work), and still had to watch out for potential data loss as a result of unpredictable crashes.
Thus began a painful, expensive, nearly endless quest to figure out why my graphics card was randomly crashing. Note: if you don’t care about the “investigation” educational part, Ctrl+F “Finding the culprit” to skip to the next part. Otherwise, read on, my geeky friend.
Potential causes I suspected:
- Linux “radeonsi” driver bug/regression (“hey, it worked before December 2015!”): unsure, but presumed.
- Some sort of SNAFU somewhere else in the stack in my Linux distribution (Fedora), ie a distro-specific bug: unsure.
- RAM errors: did memtests, no problems there.
- Capacitor plague on the motherboard: nope, it all looked good to the naked eye.
- Underpowered or failing power supply
- Linux-incompatible motherboard or BIOS
- Incompatible motherboard-and-GPU combination
For #1 and 2, I placed my hopes on the (then upcoming) Wayland-based Fedora 25 (“gotta wait for nov/december 2016”): turned out to not be the solution. Still randomly crashing.
Hypotheses #6 and 7 would be dealbreakers, where it would mean I would have wasted my money on the workstation as I would have to replace it again. My geek honor was not ready to accept that scenario.
All along, I was trying to figure out how to trigger the bug, by:
- trying to overload the system (be it the graphics card or CPU or I/O, with games/compiling/webGL demos/video playback/etc.)
- using a different graphics card (another older radeon, or a nVidia card which was impossible to get working drivers for)
- putting the card back into my older computer (and indeed the issue didn’t seem to happen there)
- transplanting (exchanging) power supplies
- spreading the load across multiple power supplies (“What if one power supply is not enough to power the Xeon and the Radeon?”)
It was absolute hell to debug/reproduce. It would sometimes crash within 10 minutes, an hour, or sometimes work for 2-3 days straight without issues, which made me question if it even worked 100.00% reliably on Kusanagi 1.0, muddying up the waters and making me waste countless week-ends and question my sanity. A true hardware heisenbug.

Throughout these tests, I was considering the possibility that Dell’s Foxconn power supply had received too much abuse from its previous owners, which seemed plausible (but can you really be sure?) as the graphics card wouldn’t crash the kernel when it was inside “Kusanagi 1.0” or when Kusanagi 1.0’s power supply was connected siamese-style with a power link across to Kusanagi 2.0:

This seemed like a good hypothesis, ergo #YOLO, I ordered a brand new power supply, the eVGA Supernova G2 series (the best I could find on the market in late 2016—I spent way too much time researching and reading reviews) and… nope, it didn’t solve the issue.

125$ wasted for the sake of the experiment (it was not economically feasible to return the power supply, so I thought I might as well keep it). At least I could say I got an extremely good silent power supply that should last me a decade or more (considering my other branded power supply from 2003 still works today).
I also tested Windows on this machine to be sure, and no matter what I tried to do to stress the system, it wouldn’t crash, an observation that threw me back to the “it’s a bug somewhere in the Linux graphics stack” theory.
Okay, so the computer crashes only on Linux. Randomly. Counterproductively. At that point I had become quite disheartened with the Linux graphics stack that was causing me such grief for months on end, and I was looking at my options:
- Go back to Kusanagi 1.0 (and lose the copious amounts of RAM).
- Run Windows: unbearable. I can’t stand this piece of crap, I feel handicapped everytime I use it.
- Make a hackintosh out of it and run Mac OS: pain in the ass, and handicapping as well.
- Buy nVidia and make it work. Ha ha ha. No.
- Resell Kusanagi 2.0, rebuild a 600-1000$ brand new Intel-only DIY workstation (Dell prices workstations at 2.5-3.5k$!) retrofitted in an old Mac Pro case.
- Wait some months/years for AMDGPU to replace radeonsi as the One and Only driver, and “hope” it is unaffected: I don’t believe in magic.
- “Just don’t stress the system”, use the computer for menial tasks: a huge waste.
Finding the culprit

Eventually, after having spent weeks testing with games, videoconferencing, video playback and WebGL demos, I started truly torturing the graphics card with “furmark” and realized the issue occurred when the card was overheating to a really high temperature (113 degrees Celsius), but only on Linux. Finally, a way to reproduce the issue reliably! And so I wrote into the bug report:
My understanding is that on Radeons (well, at least the Radeon HD 7770), there is an emergency mechanism in the hardware (or firmware/microcode maybe) that activates self-throttling of performances when the GPU reaches a critical temperature. Normally, the video driver is supposed to handle this state change gracefully, however the radeonsi/radeon/amdgpu driver on Linux does not, so the kernel panics because the driver went belly up.

“Duh! Just get better cooling!” might sound like the solution, but technically it still is a software/driver issue: the radeonsi driver on Linux does not handle the event where the hardware force-throttles itself. In Windows, breaching the 110-113 degrees Celsius limit results in the video driver simply dropping frames massively, continuing to function at reduced performance (ie: going from 40-60 fps to 10-15 fps on one of my benchmarks). The system never crashes. The Linux driver should handle such scenarios gracefully just as well as the Windows driver. At least, that’s the theory.
In practice, it would be quicker for me to solve my cooling problem than to wait for a driver bugfix. Besides, my graphics card would thank me (and provide better performance).
But wait, I’ve had the GPU since 2012, so why didn’t I encounter this with my previous computer, prior to December 2015? Because Kusanagi 2.0’s case has a different airflow and cooling behavior from Kusanagi 1.0. So now you’re asking, why didn’t I realize this during my weeks of benchmarking then? Because it was very hard to get consistent crashes (the more I tried to investigate it, the less sense it made), due to these factors:
- The Radeon 7770 I have is an “open air” cooling system which spreads the heat into the case (not a “blower” fan that exhausts outside the case), which means that for the bug to occur, the whole system has to reach a temperature plateau which might require specific CPU and GPU interaction or ambient room temperature conditions;
- I was sometimes testing with the case closed, sometimes with the case open (when trying different power supplies configurations), which threw off my results.
Anyway. At least, now I knew the cause, and therefore had a basic workaround: just keep the computer’s case open, where the heat would evacuate naturally and the graphics card would never reach the critical temperature, preventing the issue. But this looks silly and lets the dust in, so I set out to find the “proper” solution to extract the heat without needing to keep the case open.

Reworking my workstation’s thermal design beyond what Dell intended it to be
I had the following restrictions for the solution I wanted to find:
- Reasonably cheap. Otherwise I might as well just cut my losses and build a brand new machine.
- No replacing my “perfectly good” and well-tested Radeon 7770: I didn’t want to go back into the “let’s wait for Free/Open drivers to be developed for your card” cycle again. Also, see point #1.
- Super quiet. I’m an absolute maniac when it comes to having “silent” computers. I like to hear myself think. Therefore, the solution had to not only be efficient at exchanging the air between the case and the room, it also had to be nearly inaudible.
- No drilling/cutting of the case if at all possible (I don’t like irreversible mods, given how much trial-and-error is involved here).
The big challenge would be to devise something compatible with the T3500’s proprietary case and airflow design (2x120mm intake fans in a suspended cage in the front pushing air into a fanless CPU heatsink, and 2x80mm exhaust grilles at the bottom at the back):

I considered the following possibilities:
- Just replace the thermal compound on the graphics card by Arctic Silver 5 (and wait 200 hours for it to cure), and try various fan combinations to see the impact on temperatures and time-to-crash.
- Put an additional exhaust fan or two in the back in the lower half: nope, didn’t work: the hot air pocket remained in the upper half (and the power supply’s fans were not moving enough air to compensate it, either).
- Put some small turbine expansion slot fan in the back: that would certainly be ineffective (since the card is an open design instead of a blower) and very noisy.
- Leaving the case open and building a giant filter all over it.
- Cutting out a hole in the case’s door to have an exhaust fan on the side, extracting the air from the GPU’s area: last resort only.
- Watercooling the GPU, or replacing the GPU’s OEM air cooler by some aftermarket “blower” cooler… but that’s spending another pile of money that could get near the cost of a new graphics card, so it seemed beyond reason.



Replacing the GPU’s thermal compound didn’t really improve things. There was a slight improvement, but not nearly enough.
Luckily, one day my pal Youness said, “I have an all-in-one watercooler that is gathering dust inside a decommissioned PC. I might as well just give it to you”, to which I replied, “Sure—wait, what did you just say?”
A waterball’s chance in Hell
I took the watercooler and proceeded to design the airflow around it. It had a very big radiator and fan (120mm), and a fairly short pair of flexible tubes, meaning I couldn’t place the radiator at the back because the exhaust grilles were too small (80mm) and the tubes would be too short to go around the bulky graphics card.

So I had to reverse the case’s airflow: it would exhaust from the front, intake from the back, with the air passing through the CPU’s radiator while being pulled by the watercooler’s fan acting as a case exhaust fan. Essentially, two radiators from two different devices being cooled by one big fan—better hope your CPU heat doesn’t significantly affect the GPU’s radiator (luckily, it didn’t)!

The watercooler was a CPU watercooler, not actually meant to be installed on a GPU: it didn’t have compatible mounting brackets, and the contact surface was immense compared to the thumb-sized GPU die. So I used the “red mod” technique to fit it onto the GPU with zip ties. Serious business:


I tested the new setup, and it seemed to work wonders: no matter what I did, the computer was now unable to overheat, and the watercooler’s radiator fan acting as the main case exhaust was sufficient to keep both the GPU and the CPU cool, even if both are being heavily loaded simultaneously for hours on end.
To complete the set up, I gave myself a treat and replaced the (also rattling) fan from that second-hand watercooler by a Noctua NF-P12, and added two Noctua redux NF-R8 intake fans to facilitate airflow to the CPU radiator. Result: a computer that can handle any workload and stay whisper quiet.

I just had to make a new custom intake filter with a wireframe instead of solid frame, to be installed on the back of the computer, which was much less elegant than the previous front intake filter due to the odd space and shape constraints on the back of the computer:


As for the front exhaust, I screwed the watercooler’s radiator onto the front grille, and sealed everything with electric tape so that the ventilation holes would match the radiator exactly, keeping a direct airflow. It now looked like this (any resemblance with Frankenstein is purely accidental):

It all worked wonders… until it didn’t. My modification worked for exactly three months, until I moved the computer a bit and the watercooler’s previously temporary rattling “air bubbles” noise became permanent, no matter how I shook or oriented the case. To top it all, while trying to solve the air bubbles issue, the watercooler’s block had now come loose from the GPU die and I would have to re-apply thermal compound and redo the whole zip tie setup (tightening the zip ties is fairly difficult, you need two people for that).
Welcome back to hell.

Turning Hell upside down
At that point in time, a new possible approach came to my mind: rip out the watercooler, revert to an “open” air-cooled GPU, and find a way to reorient the computer case itself. I figured that if the computer was just positioned differently, to let the GPU’s rising hot air escape “naturally” from the top of the computer case (instead of having the intake and exhaust fans move presumably cold air at the bottom of the case and letting the GPU sit in a stagnant air pocket above), it might make a difference. I was ready to try anything at this point.
To test my theory, and since I thought it was probably necessary to have the exhaust directed straight upwards (and the intake below the case), I devised a pretty silly scheme to create “legs” for the back of my computer to stand on (remember, the back is where the air intake fan now was, as well as the connectivity cabling). So I literally “bricked” my computer:

The only other way would have been to have the computer suspended on steel wires, but that would be a big stress for my desk and it would also be highly impractical for servicing the machine.
Test results showed that my “bricked computer” now had the best “theoretical” airflow design indeed: with the intake at the bottom and the exhaust at the top, the computer was now completely immune to overheating, even with the case closed! Hurrah!
However, the whole set-up was a bit flimsy and looked quite silly—a 17 kg (38 lbs) computer standing in equilibrium by the edges of its chassis on two bricks on top of a towel! Seriously Anakin, look at this:

So I wondered: would it still work if I flip the entire computer case upside-down from its normal orientation, with both intake and exhaust fans being located in the top portion and moving air horizontally? I had doubts—after all, the power supply’s exhaust fan in the previous configurations had never been sufficient to get rid of the GPU’s hot air pocket, so would this really work any better?

Turns out that it did.
- The GPU remains cool in all my stress tests, as the rising heat is still correctly getting evacuated by new “horizontal air corridor” at the top of the case.
- The Xeon CPU stays cool under normal working conditions; only under heavy CPU load will its temperature rise (fairly high, up to 80-85 Celsius, due to the recycled GPU air and the absence of fans mounted directly on the Xeon’s heatsink), though it never reaches “critical” thermal limits. I thought of building an “air duct” system to force more air to pass through the CPU heatsink for the rare occasions when I’m pegging the CPU for extended periods of time, but you know what? Screw that—it works “well enough” (and running hot is what workstation-grade Xeons were designed for anyway).
As you can see, the final solution turned out to be quite trivial. So simple, in fact, I can’t believe it took me so long to find it—and that’s not for lack of online research, discussion with fellow geeks, or thinking hard about the problem as a certified geek.
Epilogue

The story ends as I have achieved workstation nirvana (it really is my favorite computer now, making any work enjoyable), after spending 18 21 months to troubleshoot and fix what I thought was a software issue, then a hardware issue, then “a little bit of both” 😓
I ended up spending a grand total of 555 C$ on the whole setup (370$ for the computer, 125$ for the unecessary power supply, 60$ for top-of-the-line fans), but that is still quite inexpensive (a brand new silent computer with that kind of power would run in the thousands of dollars). Just ignore the “opportunity cost” of my hourly rate when it comes to the time I spent on this!
That said, I learned a lot in the process, and that’s priceless. I hope this troubleshooting tale can help others too—or that you at least had a good laugh at my persistence in repurposing a legacy system into an unstoppable silent powerhouse that crushes most machines we see out there even today.
Hmm? What is it you’re saying? All mainstream CPUs made since the original Pentium have now been found to be vulnerable to a fundamental architectural flaw and we need to get brand new CPUs designed as of 2018? Well,

P.s.: feel free to retweet this or retoot that 😉

You can check out my main website, find me on Twitter or Mastodon or subscribe to my YouTube channel.
Comments
10 responses to “The Longest Debugging—The journey towards a reliable Linux workstation”
What an interesting article! Especially with the Ghost in the Shell references. Thanks a lot!
A great read, thanks!
Oh my goodness! That was both fascinating and painful to read. Thanks for sharing! I hope your new setup lasts a looooong time. 🙂
Awesome story, thanks for sharing :). Now you only have that gnome-shell framerate dropping to investigate and you’re done :D.
Thanks folks, I’m really happy to see you found the story entertaining 🙂
Wow this hits home on two levels:
After your experience with heating problems. What silent fans do you recommend? I may need some of those for my system.
Well, if you have the money to burn on these things, the Noctua fans are kind of infamous for being the best things you can get—with a hefty pricetag. They have three main lines: the standard (brown) ones, the “redux” line (previous generation at a discounted price) and the “industrial” line (even pricier than the regular ones, noisier, and probably pointless unless you’re building servers in the desert). And, well, let’s just ignore the fourth (“chromax”) line because it’s kind of silly.
If you don’t have that kind of money to splurge with, generally just get fans that are as large as possible and that can spin slowly (ex: 1000 rpm or less). You may have to check the distinction between fans optimized for “static pressure” vs fans designed for “airflow”.
I will admit that this sort of terrifying horror story exemplifies why I get my machines built for me by Yamaha’s cyberbrain division uh I mean various custom-assembly houses that are willing to do small jobs for private individuals, and then torture the hell out of them every way I can think of before putting any kind of important stuff on them. Sure, this means I have to wait a month or two before using my lovely new toys — but it also means the infant mortality phase is probably past, and it means I get to watch the bastard work for a while, even if it’s makework. It is true that this approach costs a lot more than yours, but when you have coordination like mine there is just no other choice: I tried taking the cooling fan off a CPU once and I don’t think any component on the motherboard survived the resulting disaster.
The nature of burnin tests is interesting: yours were wildly different from any of mine but probably well-targetted at a graphics-related problem. As someone who uses the graphics stuff just for Glamor’s 2D stuff but does massive amounts of compiling, I tend to use GCC parallel (these days LTO) bootstrap-and-test runs in an endless loop as my torture test, comparing the test results every time to ensure they stay unchanged, with an NFS-mounted srcdir and the objdir on the local disk, to torture the CPU, disk, and network at various times, while ensuring that even a single bitflip will cause extra test failures. This is a lot more effective than the usual “oh just compile a kernel a lot” approach, because those kernels aren’t tested: if a kernel gets intermittently miscompiled in a test like that, you’re stuck: you just have to hope that some bitflip screws up GCC’s pointer-chasing enough that it segfaults it and triggers its “auto-recompile oops it worked this time you have a hardware problem” machinery. Many failures don’t, but if you miscompile the compiler that is then used to compile the next stage of the compiler bootstrap, you *will* find out: similarly if it’s then used to run the hundred thousand-odd tests in the GCC testsuite in parallel: at least one test is likely to fail that didn’t before. (Assuming the whole machine doesn’t MCE or the disk vanish off the bus or the network just go down and not come up.)
This has been a very successful burnin test over the years, finding power supply, DRAM, PCIe circuit trace and even CPU cache problems, often multiple of them on the same machine (I don’t buy that many machines, but it’s surprising how few survive the initial burnin without problems!): I suspect most people who say they want workstations don’t want them to do actual, y’know, work but just to look cool, so I guess some places economize on parts a bit and then suffer when someone like me comes along: yes I really will be running fifty-hour-long compile jobs on this machine many many times, yes it must work and work consistently! Because I had them custom-built I didn’t need to track the problems down, just throw the box back at the assembler with a USB key that ran the burnin tests on the local disk only and ask them to do it!
Oh and this found cooling problems. Really bad cooling problems, though the really scary one, when actual flames came out of the case, was not actually the machine catching fire but a piece of cardboard the assemblers had accidentally left in the machine bursting into flames when the CPU, perhaps 10cm from it, hit 100C for long enough.)
I’m glad/sad to see I’m not the only one frustrated by the horrible Linux OOM behavior, usually triggered by Firefox. I feel like it only has gotten worse recently.
What a fantastic bit of cooling, modding, HW pr0n. Thoroughly enjoyed the article. Excellent troubleshooting overview and one that I wish more people understood.